linux学习笔记第二篇之bash
快捷键
^u向前删除所有;^k向后删除所有^a(ahead)移至最前面,^e(end)移至最后
变量
内置变量例如PATH,HOME,RANDOM
1 | [dmtsai@study ~]$ declare -i number=$RANDOM*10/32768 ; echo $number |
获取环境变量
env(所有bash都具有的变量).获取环境变量和自订变量set将临时变量变为环境变量
export var,获取当前的环境变量export1
2
3
4
5
6
7work=/home/s0me/tmp
export work #当前bash和所有的子进程的环境变量,新的bash shell中并不会有此变量
#只能将某个变量设为子进程和当前进程的环境变量
bash #打开新的bash子进程
cd $work #成功的进入了设定好的work目录
exit #关闭子bash进程
变量取用
$var or ${var}
1 | echo $HOME #输出 /home/dream |
变量设定规则
1 | ######变量后的注释行均为执行 echo ${变量} 之后的输出 ###### |
=连接,且等号两侧无空白字符- 变量中有空白字符,可用引号将变数内容结合起来
"双引号保留特殊字符原有特性'单引号全为一般字符
\转义功能,注意可将[sapce]转义, 即var=i\ am\ foo是合法语句- 一串指令调用其他指令,可以用 [`指令`] 或者[$(指令)] 优先调用
- 扩增变量内容,直接在
[${指令}]或者[" $指令"]后连接即可 - 特别注意:
反单引号,
$(指令)(小括号)只能包含指令;${变量}(中括号)只能包含变量 - 若该变量需要在其他子程序执行,则需要以export来使变量变成环境变量
export var - 取消变量
unset
一些常用变量
PS1命令提示字元,即s0me@s0me-Laptop:~$\d:可显示出『星期月日』的日期格式,如:"Mon Feb 2"\H:完整的主机名称。举例来说,鸟哥的练习机为『study.centos.vbird』\h:仅取主机名称在第一个小数点之前的名字,如鸟哥主机则为『study』后面省略\t:显示时间,为24 小时格式的『HH:MM:SS』\T:显示时间,为12 小时格式的『HH:MM:SS』\A:显示时间,为24 小时格式的『HH:MM』\@:显示时间,为12 小时格式的『am/pm』样式\u:目前使用者的帐号名称,如『dmtsai』;\v:BASH 的版本资讯,如鸟哥的测试主机版本为4.2.46(1)-release,仅取『4.2』显示\w:完整的工作目录名称,由根目录写起的目录名称。但家目录会以~ 取代;\W:利用basename 函数取得工作目录名称,所以仅会列出最后一个目录名。\#:下达的第几个指令。\$:提示字元,如果是root 时,提示字元为# ,否则就是$ 啰~
1 | #example 01 |
$目前shell的进程号.echo $$,会返回目前shell的 pid?上一条指令的传回值echo $?为0,表示上一条指令执行成功,不为0,表示执行错误
设定语系
locale -a显示当前支持的所有语言locale显示当前语言相关的环境变量,一般修改LANG即可1
2
3
4
5
6
7
8
9[dmtsai@study ~]$ locale <==后面不加任何选项与参数即可!
LANG=en_US <==主语言的环境
LC_CTYPE="en_US" <==字元(文字)辨识的编码
LC_NUMERIC="en_US" <==数字系统的显示讯息
LC_TIME="en_US" <==时间系统的显示资料
LC_COLLATE="en_US" <==字串的比较与排序等
LC_MONETARY="en_US" <==币值格式的显示等
LC_MESSAGES="en_US" <==讯息显示的内容,如功能表、错误讯息等
LC_ALL= <==整体语系的环境如果不生效可用
export进行一下转换
读取键盘输入
命令 read
1 | $ read [-pt] var |
变量类型声明
命令declare
变量类型预设为字符串
1 | $ declare [-aixr] variable |
数组(array)变量类型
设定方法 var[index]=content , \(index \in [0, +\infin)\).
限制可用资源
命令 ulimit [-SHacdfltu] [配额]
1 | [dmtsai@study ~]$ ulimit [-SHacdfltu] [配额] |
变量内容的删除,取代与替换(optimal)
删除与取代
注意删除内容一定从某一端开始并包含某一端,不能单独删除中间一段
#从开始删除 第一个 最短符合通配符的##从开始删除 第一个 最长符合通配符的%从结尾开始 第一个 最短符合通配符的%%从结尾开始 第一个 最长符合通配符的
1 | s0me@s0mE-laptop:~$ echo ${PATH} |
${var/old_str/new_str}替换第一个符合旧字串的字符串${var//old_str/new_str}替换全部符合旧字串的字符串
变量的测试与内容替换
- 判断变量是否存在(即是否初始化过)或者是否为空字符串
| 变数设定方式 | str 没有设定 | str 为空字串 | str 已设定非为空字串 |
|---|---|---|---|
| var=${str-expr} | var=expr | var= | var=$str |
| var=${str:-expr} | var=expr | var=expr | var=$str |
| var=${str+expr} | var= | var=expr | var=expr |
| var=${str:+expr} | var= | var= | var=expr |
| var=${str=expr} | str=expr var=expr | str不变 var= | str不变 var=$str |
| var=${str:=expr} | str=expr var=expr | str=expr var=expr | str不变 var=$str |
| var=${str?expr} | expr 输出至stderr | var= | var=$str |
| var=${str:?expr} | expr 输出至stderr | expr 输出至stderr | var=$str |
命令别名与历史命令
- 命令别名
alias,unalias - 历史命令
history,history 5可以查询最近五次的命令 !n执行第n次命令!!执行上一次命令!al执行最近的以al开头的那个指令
Shell 的操作环境
路径与指令搜索顺序
- 相对路径
- alias寻找
- bash内置指令寻找
- 通过$PATH变量查找
bash的进站与欢迎讯息
终端进站提示信息
cat /etc/issue内部代码含义
1
2
3
4
5
6
7
8
9\d本地端时间的日期;
\l显示第几个终端机介面;
\m显示硬体的等(i386/i486/i586/i686...);
\n显示主机的网路名称;
\O显示domain name;
\r作业系统的版本(相当于uname -r)
\t显示本地端时间的时间;
\S作业系统的名称;
\v作业系统的版本。
/etc/issue.net提供给telnet连接/etc/motd你编写的给所有登陆者的信息
bash的环境设定档
login 与 non-login shell
login shell
1.etc/profile包含环境变量,呼叫如下文档:
1 | /etc/profile.d/*.sh #包含命令别名 |
2.~/.bash_profile or~/.bash_login or
~/.profile,包含用户个人设定,会呼叫~/.bashrc
non-login shell
只会读取~/.bashrc
source 命令
source xxx or . xxx,
读入文档xxx的设定, 无需重启系统,即可使自己的修改生效
其他设定文档
1 | /etc/man_db.conf # man page 查找路径 |
终端机(tty)的环境设定: stty, set
stty
1 | $ stty [-a] |
常用按键对照表如下
| 变量 | 快捷键 | 含义 |
|---|---|---|
| intr | 【ctrl+c】【^c】 | 发送一个interrupt (中断) 的讯号给目前正在run的程序 |
| quit | 【ctrl+】【^】 | 发送一个quit 的讯号给目前正在run的程序 |
| erase | 【ctrl+?】【^?】【backsapce键】 | 删除字符(删除键用^?表示,很有意思) |
| kill | 【ctrl+u】【^u】 | 删除在目前指令列上光标前的所有文字 |
| eof | 【ctrl+d】【^d】 | End of file 的意思,代表『结束输入』 |
| start | 【ctrl+q】【^q】 | 在某个程序停止后,重新启动他的output |
| stop | 【ctrl+s】【^s】 | 停止目前屏幕的输出(程序仍然在运行) |
| susp | 【ctrl+z】【^z】 | 送出一个terminal stop(终端停止)的讯号给正在run的程序 |
修改设定方法
1 | $ stty erase ^h #这个设定看看就好,不必真的实做!不然还要改回来! |
set
-启用相应设定,+取消相应设定
1 | $ set [-uvCHhmBx] |
万用字符和特殊符号
万用字符
| 符号 | 意义 |
|---|---|
| * | 『 0 个到无穷多个』任意字元 |
| ? | 『一定有一个』任意字元 |
| [ ] | 『一定有一个在括号内』的字元(非任意字元)。[abcd] 代表『一定有一个字元,可能是a, b, c, d 这四个任何一个』 |
| [ - ] | 若有减号在中括号内时,代表『在编码顺序内的所有字元』。例如[0-9] 代表 0 到9 之间的所有数字 |
| [^ ] | 若中括号内的第一个字元为指数符号(^)
,那表示『反向选择』,例如·[^abc]
代表一定有一个字元,只要是非a, b, c 的其他字元就接受的意思。 |
特殊符号
| 符号 | 内容 |
|---|---|
| # | 注解符号:这个最常被使用在script 当中,视为说明!在后的资料均不执行 |
| \ | 跳脱符号:将『特殊字元或万用字元』还原成一般字元 |
| | | 管线(pipe):分隔两个管线命令的界定(后两节介绍); |
| ; | 连续指令下达分隔符号:连续性命令的界定(注意!与管线命令并不相同) |
| ~ | 使用者的家目录 |
| $ | 取用变数前置字元:亦即是变数之前需要加的变数取代值 |
| & | 工作控制(job control):将指令变成背景下工作 |
| ! | 逻辑运算意义上的『非』 not 的意思! |
| / | 目录符号:路径分隔的符号 |
| >, >> | 资料流重导向:输出导向,分别是『取代』与『累加』 |
| <, << | 资料流重导向:输入导向(这两个留待下节介绍) |
| ' ' | 单引号,不具有变数置换的功能($ 变为纯文字) |
| " " | 具有变数置换的功能!($ 可保留相关功能) |
| ` ` | 两个『 ` 』中间为可以先执行的指令,亦可使用$( ) |
| ( ) | 在中间为子shell 的起始与结束 |
| { } | 在中间为命令区块的组合! |
数据流重定向
重定向简介
三种数据流 stdout,
stdin, stderr
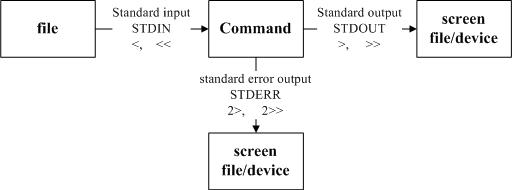
| 类型 | 代码 | 符号 |
|---|---|---|
| 标准输入(stdin) | 0 | < 或<< |
| 标准输出(stdout) | 1 | > 或>>; 1>或1>>也可 |
| 标准错误输出(stderr) | 2 | 2> 或2>> |
单个>表示以覆盖方式输出,两个>>表示以追加的方式输出
单个<表示以后面的文件为标准输入,两个<<后面表示自己定义的输入结束标志符
1 |
|
dev/null垃圾桶黑洞
1 | # 范例四:承范例三,将错误的资料丢弃,萤幕上显示正确的资料 |
将正确与错误输出写入同一个文件
2>&1将2号输出流重定向至1号输出流,
1>&2同理
1 |
|
stdin < 与 <<
cat 创建文档 cat > catfile
1 | # 利用cat指令来建立一个档案的简单流程 |
命令执行判断依据: ;, &&, ||
cmd ; cmd
不考虑指令相关性的连续指令下达
$? (指令回传值) 与&& 或||
单独指令含义如下
| 指令下达情况 | 说明 |
|---|---|
| cmd1 && cmd2 | cmd1执行完毕后, 若正确执行($? == 0),则执行cmd2。否则不执行。 |
| cmd1 || cmd2 | cmd1执行完毕后, 若未正确执行($? != 0),则cmd2执行。 否则不执行。 |
不同的连接顺序含义不同
| 指令 | 含义 |
|---|---|
| cmd1 && cmd2 || cmd3 | 如果cmd1正确运行则执行cmd2,否则执行cmd3 |
| cmd1 || cmd2 && cmd3 | 如果cmd1错误运行则执行cmd2,并执行cmd3,否则执行cmd3 |
ps: 以上前提是cmd2,cmd3一旦执行都能正常运行
管线命令(pipe)
一般仅能处理stdout,
会忽略stderr,不过可以通过2>&1处理stderr
撷取命令: cut, grep
cut
分解同一行的信息
1 | $ cut -d '分隔字元' -f fields # <==用于有特定分隔字元 |
grep
分析一行信息,如果包含我们想要的信息,则取出该行。
1 | $ grep [-acinv] [--color=auto] '搜寻字串' filename |
排序命令:sort, wc, uniq
sort
1 | $ sort [-fbMnrtuk] [file or stdin] |
uniq
重复的资料仅列出一个显示
1 | $ uniq [-ic] |
wc
1 | $ wc [-lwm] |
双向重导向 tee

tee功能如图所示,tee输出到screen其实就是 stdout.
1 | $ tee [-a] file |
字元转换命令 tr, col, join, paste, expand
tr
tr 可以用来删除一段讯息当中的文字,或者是进行文字讯息的替换!
1 | $ tr [-ds] SET1 ... |
col
将[tab] 按键取代成为空白键
1 | $ col [-xb] |
join
对比两个档案,将有"相同资料" 的行对应合并为一行,注意先排序,否则会少合并
1 | $ join [-ti12] file1 file2 |
paste
将两行贴在一起,且中间以[tab]键隔开
1 | $ paste [-d] file1 file2 |
expand
将[tab] 按键转成空白键
1 | $ expand [-t] file |
分割命令:split
将大档案分割成小档案
1 | $ split [-bl] file PREFIX |
参数代换:xargs
产生某个指令的参数,xargs可以读入stdin的资料,并且以空白字元或断行字元作为分辨,将stdin的资料分隔成为arguments 。
很多指令其实并不支援管线命令,因此我们可以透过xargs来提供该指令引用standard input之用
1 | $ xargs [-0epn] command |
关于减号 - 的用途
管线命令在bash 的连续的处理程序中是相当重要的!另外,在log file 的分析当中也是相当重要的一环, 所以请特别留意!另外,在管线命令当中,常常会使用到前一个指令的stdout 作为这次的stdin , 某些指令需要用到档案名称(例如tar) 来进行处理时,该stdin 与stdout 可以利用减号"-" 来替代, 举例来说:
1 | $ mkdir /tmp/homeback |
减号相当于stdin,stdout的跳转管道